Problem Statement: -
A report that provides the pairs (actor_id, director_id) where the actor has cooperated with the director at least 3 times.
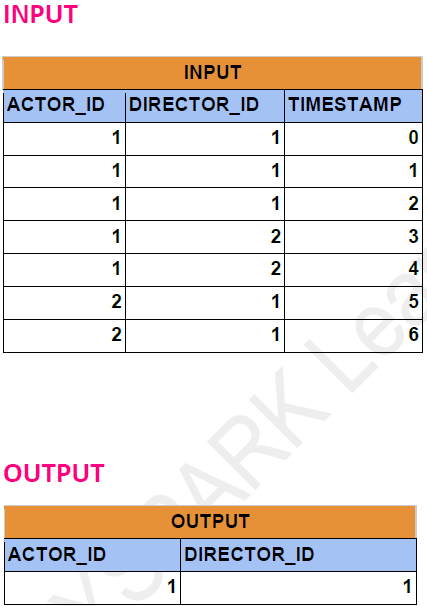
Dataframe API solution: -
from pyspark.sql.functions import *
from pyspark.sql.types import *
schema = StructType([
StructField("ActorId",IntegerType(),True),
StructField("DirectorId",IntegerType(),True),
StructField("timestamp",IntegerType(),True)
])
data = [
(1, 1, 0),
(1, 1, 1),
(1, 1, 2),
(1, 2, 3),
(1, 2, 4),
(2, 1, 5),
(2, 1, 6)
]
df = spark.createDataFrame(data,schema)
df.show()
+-------+----------+---------+
|ActorId|DirectorId|timestamp|
+-------+----------+---------+
| 1| 1| 0|
| 1| 1| 1|
| 1| 1| 2|
| 1| 2| 3|
| 1| 2| 4|
| 2| 1| 5|
| 2| 1| 6|
+-------+----------+---------+
df_grouped = df.groupBy('ActorId','DirectorId').count()
df_grouped.show()
+-------+----------+-----+
|ActorId|DirectorId|count|
+-------+----------+-----+
| 1| 1| 3|
| 1| 2| 2|
| 2| 1| 2|
+-------+----------+-----+
df_result = df_grouped.filter(df_grouped["count"] >= 3).select("ActorId","DirectorId")
# Or .filter(col("count") >= 3)
df_result.show()
+-------+----------+
|ActorId|DirectorId|
+-------+----------+
| 1| 1|
+-------+----------+
SparkSQL Solution: -
df = spark.createDataFrame(data,schema)
df.createOrReplaceTempView("Actors")
result = spark.sql("""
SELECT
ActorId,
DirectorId
FROM actors
GROUP BY ActorId,DirectorId
HAVING COUNT(*) >=3
""")
result.show()