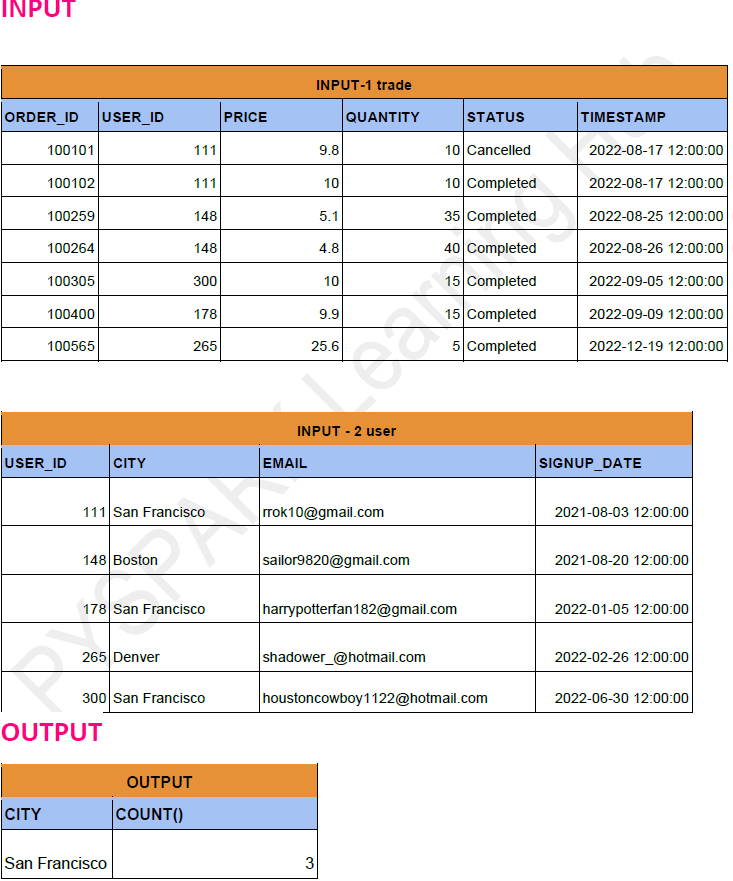
Problem Statement: -
Retrieve the top three cities that have the highest number of completed trade orders listed in descending order. Output the city name and the corresponding number of completed trade orders.

Dataframe API Solution: -
from pyspark.sql.types import *
from pyspark.sql.functions import *
from pyspark.sql.window import *
trades_schema = StructType([ StructField("order_id", IntegerType(), True), StructField("user_id", IntegerType(), True), StructField("price", FloatType(), True), StructField("quantity", IntegerType(), True), StructField("status", StringType(), True), StructField("timestamp", StringType(), True) ])
# Define the schema for the users
users_schema = StructType([ StructField("user_id", IntegerType(), True), StructField("city", StringType(), True), StructField("email", StringType(), True), StructField("signup_date", StringType(), True) ])
trades_data = [ (100101, 111, 9.80, 10, 'Cancelled', '2022-08-17 12:00:00'), (100102, 111, 10.00, 10, 'Completed', '2022-08-17 12:00:00'), (100259, 148, 5.10, 35, 'Completed', '2022-08-25 12:00:00'), (100264, 148, 4.80, 40, 'Completed', '2022-08-26 12:00:00'), (100305, 300, 10.00, 15, 'Completed', '2022-09-05 12:00:00'), (100400, 178, 9.90, 15, 'Completed', '2022-09-09 12:00:00'), (100565, 265, 25.60, 5, 'Completed', '2022-12-19 12:00:00') ]
users_data = [ (111, 'San Francisco', 'rrok10@gmail.com', '2021-08-03 12:00:00'), (148, 'Boston', 'sailor9820@gmail.com', '2021-08-20 12:00:00'), (178, 'San Francisco', 'harrypotterfan182@gmail.com', '2022-01-05 12:00:00'), (265, 'Denver', 'shadower_@hotmail.com', '2022-02-26 12:00:00'), (300, 'San Francisco', 'houstoncowboy1122@hotmail.com', '2022-06-30 12:00:00') ]
trades_df = spark.createDataFrame(trades_data,trades_schema)
users_df = spark.createDataFrame(users_data,users_schema)
trades_df.show()
users_df.show()
+--------+-------+-----+--------+---------+-------------------+
|order_id|user_id|price|quantity| status| timestamp|
+--------+-------+-----+--------+---------+-------------------+
| 100101| 111| 9.8| 10|Cancelled|2022-08-17 12:00:00|
| 100102| 111| 10.0| 10|Completed|2022-08-17 12:00:00|
| 100259| 148| 5.1| 35|Completed|2022-08-25 12:00:00|
| 100264| 148| 4.8| 40|Completed|2022-08-26 12:00:00|
| 100305| 300| 10.0| 15|Completed|2022-09-05 12:00:00|
| 100400| 178| 9.9| 15|Completed|2022-09-09 12:00:00|
| 100565| 265| 25.6| 5|Completed|2022-12-19 12:00:00|
+--------+-------+-----+--------+---------+-------------------+
+-------+-------------+--------------------+-------------------+
|user_id| city| email| signup_date|
+-------+-------------+--------------------+-------------------+
| 111|San Francisco| rrok10@gmail.com|2021-08-03 12:00:00|
| 148| Boston|sailor9820@gmail.com|2021-08-20 12:00:00|
| 178|San Francisco|harrypotterfan182...|2022-01-05 12:00:00|
| 265| Denver|shadower_@hotmail...|2022-02-26 12:00:00|
| 300|San Francisco|houstoncowboy1122...|2022-06-30 12:00:00|
+-------+-------------+--------------------+-------------------+
trades_filtered_df = trades_df.filter(col("status") == "Completed")
joined_df = trades_filtered_df.join(users_df,trades_filtered_df.user_id == users_df.user_id).groupBy("City").count()
window_spec = Window.orderBy(desc("count"))
ranked_df = joined_df.withColumn("Rank",rank().over(window_spec))
result_df = ranked_df.select("City","Count").filter(col("Rank")<=3)
result_df.show()
+-------------+-----+
| City|Count|
+-------------+-----+
|San Francisco| 3|
| Boston| 2|
| Denver| 1|
+-------------+-----+
Spark SQL Solution: -
trades_df.createOrReplaceTempView("trades")
users_df.createOrReplaceTempView("users")
result = spark.sql("""
WITH CTE AS (
SELECT
u.city,
COUNT(*) AS CNT,
RANK() OVER (ORDER BY COUNT(*) DESC) AS RNK
FROM trades t JOIN users u ON t.user_id = u.user_id
WHERE status = "Completed"
GROUP BY u.city
)
SELECT
City,
CNT
FROM CTE
WHERE RNK <=3
""")
result.show()