Problem Statement: -
Report the first name, last name, city, and state of each person in the Person dataframe. If the address of a personId is not present in the Address dataframe, report null instead.
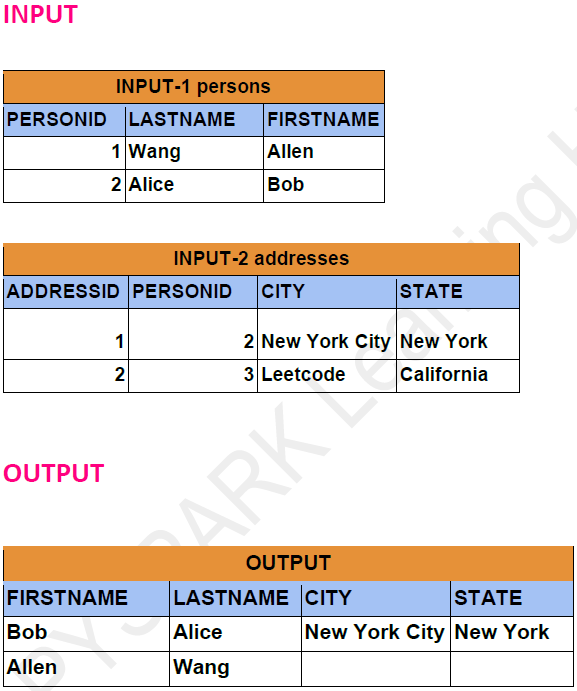
Dataframe API Solution: -
from pyspark.sql.types import *
# Define schema for the 'persons' table
persons_schema = StructType([
StructField("personId", IntegerType(), True),
StructField("lastName", StringType(), True),
StructField("firstName", StringType(), True)
])
# Define schema for the 'addresses' table
addresses_schema = StructType([
StructField("addressId", IntegerType(), True),
StructField("personId", IntegerType(), True),
StructField("city", StringType(), True),
StructField("state", StringType(), True)
])
# Define data for the 'persons' table
persons_data = [
(1, 'Wang', 'Allen'),
(2, 'Alice', 'Bob')
]
# Define data for the 'addresses' table
addresses_data = [
(1, 2, 'New York City', 'New York'),
(2, 3, 'Leetcode', 'California')
]
person_df = spark.createDataFrame(persons_data,persons_schema)
address_df = spark.createDataFrame(addresses_data,addresses_schema)
person_df.show()
address_df.show()
+--------+--------+---------+
|personId|lastName|firstName|
+--------+--------+---------+
| 1| Wang| Allen|
| 2| Alice| Bob|
+--------+--------+---------+
+---------+--------+-------------+----------+
|addressId|personId| city| state|
+---------+--------+-------------+----------+
| 1| 2|New York City| New York|
| 2| 3| Leetcode|California|
+---------+--------+-------------+----------+
result_df = person_df.join(address_df,person_df.personId == address_df.personId,'left') \
.select("firstname","lastname","city","state")
result_df.show()
+---------+--------+-------------+--------+
|firstname|lastname| city| state|
+---------+--------+-------------+--------+
| Allen| Wang| NULL| NULL|
| Bob| Alice|New York City|New York|
+---------+--------+-------------+--------+