Problem Statement: -
Find Employees Earning More Than Their Managers.
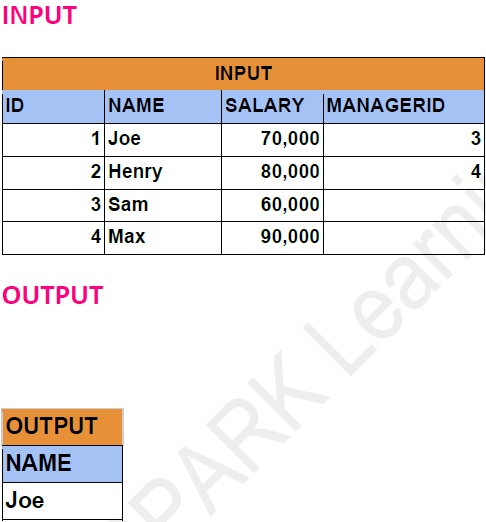
DataFrame API Solution: -
from pyspark.sql.types import *
# Define the schema for the "employees"
employees_schema = StructType([
StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("salary", IntegerType(), True),
StructField("managerId", IntegerType(), True)
])
# Define data for the "employees"
employees_data = [
(1, 'Joe', 70000, 3),
(2, 'Henry', 80000, 4),
(3, 'Sam', 60000, None),
(4, 'Max', 90000, None)
]
df = spark.createDataFrame(employees_data,employees_schema)
df.show()
+---+-----+------+---------+
| id| name|salary|managerId|
+---+-----+------+---------+
| 1| Joe| 70000| 3|
| 2|Henry| 80000| 4|
| 3| Sam| 60000| NULL|
| 4| Max| 90000| NULL|
+---+-----+------+---------+
emp_df1 = df.alias("emp")
emp_df2 = df.alias("mngr")
self_joined_df = emp_df1.join(emp_df2,col("emp.ManagerId") == col("mngr.id"),"inner")
self_joined_df.show()
+---+-----+------+---------+---+----+------+---------+
| id| name|salary|managerId| id|name|salary|managerId|
+---+-----+------+---------+---+----+------+---------+
| 1| Joe| 70000| 3| 3| Sam| 60000| NULL|
| 2|Henry| 80000| 4| 4| Max| 90000| NULL|
+---+-----+------+---------+---+----+------+---------+
result_df = self_joined_df.filter(col("emp.salary")>col("mngr.salary")).select("emp.name")
result_df.show()
+----+
|name|
+----+
| Joe|
+----+
Spark SQL Solution: -
df.createOrReplaceTempView("Emp")
result = spark.sql("""
SELECT
e.name
FROM Emp e join Emp m ON e.managerId = m.id
WHERE e.salary > m.salary
""")
result.show()