Problem Statement: -
Find the first login date for each player. Return the result table in any order.
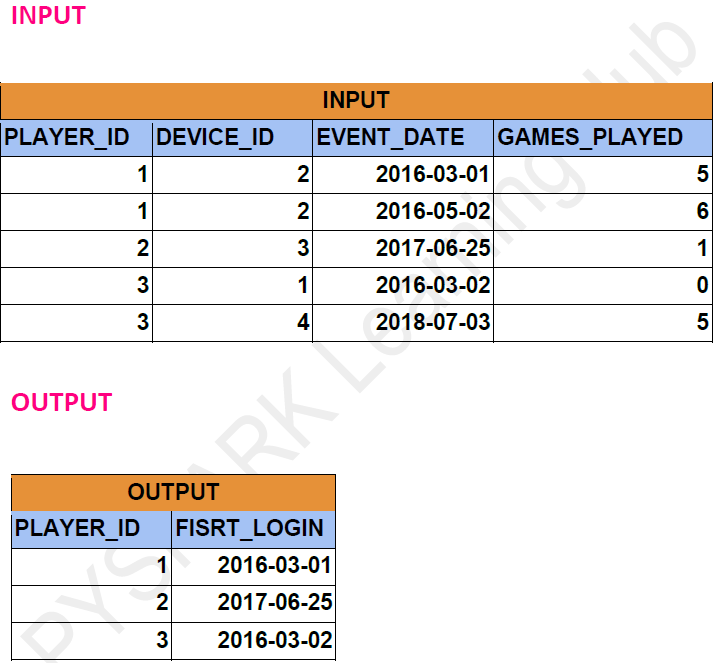
Dataframe API Solution: -
from pyspark.sql.types import *
from pyspark.sql.functions import *
from pyspark.sql.window import *
# Define the schema for the "Activity"
activity_schema = StructType([ StructField("player_id", IntegerType(), True),
StructField("device_id", IntegerType(), True),
StructField("event_date", StringType(), True),
StructField("games_played", IntegerType(), True) ])
# Define data for the "Activity"
activity_data = [ (1, 2, '2016-03-01', 5),
(1, 2, '2016-05-02', 6),
(2, 3, '2017-06-25', 1),
(3, 1, '2016-03-02', 0),
(3, 4, '2018-07-03', 5) ]
df = spark.createDataFrame(activity_data,activity_schema)
df = df.withColumn("event_date",to_date("event_date","yyyy-MM-dd"))
df.show()
df.printSchema()
+---------+---------+----------+------------+
|player_id|device_id|event_date|games_played|
+---------+---------+----------+------------+
| 1| 2|2016-03-01| 5|
| 1| 2|2016-05-02| 6|
| 2| 3|2017-06-25| 1|
| 3| 1|2016-03-02| 0|
| 3| 4|2018-07-03| 5|
+---------+---------+----------+------------+
root
|-- player_id: integer (nullable = true)
|-- device_id: integer (nullable = true)
|-- event_date: date (nullable = true)
|-- games_played: integer (nullable = true)
window_spec = Window.partitionBy("player_id").orderBy(col("event_date"))
res_df = df.withColumn("first_login",first_value(col("event_date")).over(window_spec))
result_df = res_df.select("player_id","first_login").distinct()
result_df.show()
+---------+-----------+
|player_id|first_login|
+---------+-----------+
| 1| 2016-03-01|
| 2| 2017-06-25|
| 3| 2016-03-02|
+---------+-----------+
Spark SQL Solution: -
df.createOrReplaceTempView("Games")
result_df = spark.sql("""
SELECT DISTINCT
player_id,
first_value(event_date) OVER (PARTITION BY player_id ORDER BY event_date) AS First_login
FROM Games
""")
result_df.show()