Problem Statement: -
Given csv file with different delimiter, get the output as shown: -
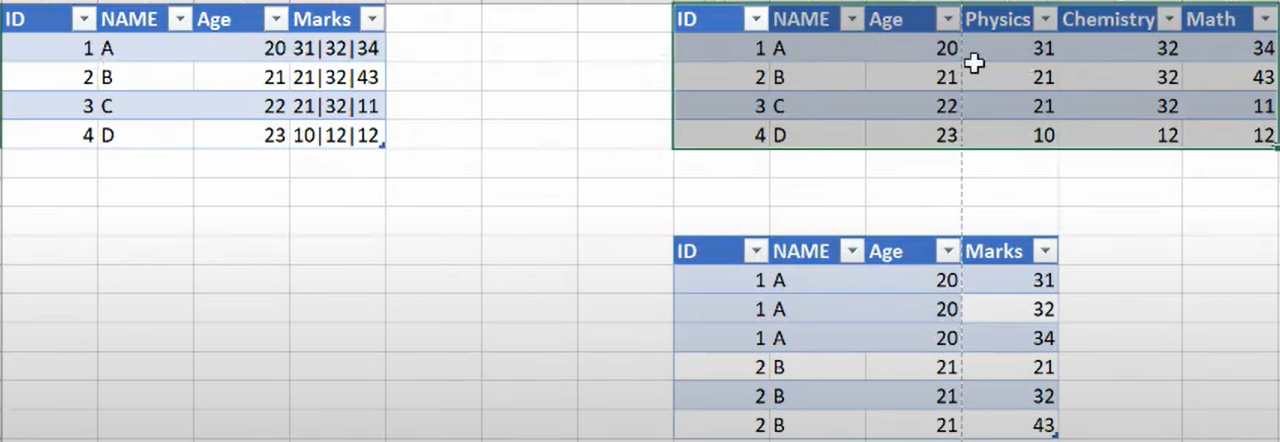
Dataframe API Solution: -
from pyspark.sql.functions import *
df = spark.read.option("header",True).format("csv").csv("Files/Book1.csv")
df.show()
+---+----+---+--------+
| ID|NAME|AGE| Marks|
+---+----+---+--------+
| 1| A| 20|31|32|34|
| 2| B| 21|21|32|43|
| 3| C| 22|12|37|11|
| 4| D| 23|20|28|45|
+---+----+---+--------+
df_ind = df.withColumn("Physics",split(col("Marks"),"\|")[0]) \
.withColumn("Chem",split(col("Marks"),"\|")[1]) \
.withColumn("Maths",split(col("Marks"),"\|")[2]) \
.drop("Marks")
df_ind.show()
+---+----+---+-------+----+-----+
| ID|NAME|AGE|Physics|Chem|Maths|
+---+----+---+-------+----+-----+
| 1| A| 20| 31| 32| 34|
| 2| B| 21| 21| 32| 43|
| 3| C| 22| 12| 37| 11|
| 4| D| 23| 20| 28| 45|
+---+----+---+-------+----+-----+
To match a literal pipe character (|), you need to escape it with a backslash (\) to tell the regex engine to treat it as a normal character rather than as an OR operator.
Example:
- Without escape:
abc|defmeans "match eitherabcordef." - With escape:
abc\|defmeans "match the stringabc|def" (literal pipe betweenabcanddef).
So, \| ensures that the regex engine matches the literal pipe symbol instead of interpreting it as an OR operator.
df_split = df.withColumn("Marks",split(col("Marks"),"\|")).select("ID","NAME","AGE",explode("Marks").alias("Marks"))
df_split.show()
+---+----+---+-----+
| ID|NAME|AGE|Marks|
+---+----+---+-----+
| 1| A| 20| 31|
| 1| A| 20| 32|
| 1| A| 20| 34|
| 2| B| 21| 21|
| 2| B| 21| 32|
| 2| B| 21| 43|
| 3| C| 22| 12|
| 3| C| 22| 37|
| 3| C| 22| 11|
| 4| D| 23| 20|
| 4| D| 23| 28|
| 4| D| 23| 45|
+---+----+---+-----+
Spark SQL Solution: -
df.createOrReplaceTempView("marks")
sqlq = """
SELECT
ID,
NAME,
Age,
SPLIT(Marks,"\\\\|")[0] AS Physics,
SPLIT(Marks,"\\\\|")[1] AS Chem,
SPLIT(Marks,"\\\\|")[2] AS Maths
FROM marks
"""
sqlq1 = """
SELECT
ID,
NAME,
Age,
EXPLODE(SPLIT(Marks,"\\\\|")) AS Marks
FROM marks
"""
res = spark.sql(sqlq)
res.show()
res1 = spark.sql(sqlq1)
res1.show()