Problem Statement: -
Transform the DataFrame to display each student's marks in Math and English as
separate columns.
Dataframe API Solution: -
from pyspark.sql.types import *
from pyspark.sql.functions import *
data=[
('Rudra','math',79),
('Rudra','eng',60),
('Shivu','math', 68),
('Shivu','eng', 59),
('Anu','math', 65),
('Anu','eng',80)
]
schema = StructType([
StructField("Name", StringType(), True),
StructField("Sub", StringType(), True),
StructField("Marks", IntegerType(), True)
])
df = spark.createDataFrame(data,schema)
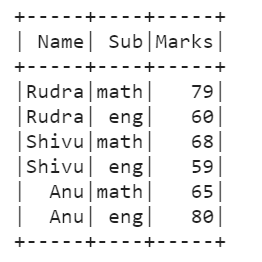
df.show()
+-----+----+-----+
| Name| Sub|Marks|
+-----+----+-----+
|Rudra|math| 79|
|Rudra| eng| 60|
|Shivu|math| 68|
|Shivu| eng| 59|
| Anu|math| 65|
| Anu| eng| 80|
+-----+----+-----+
df_list = df.groupBy("Name").agg(collect_list("Marks").alias("Marks_list"))
res_df = df_list.withColumn("Math",col("Marks_list")[0]) \
.withColumn("Eng",col("Marks_list")[1]).drop("Marks_list")
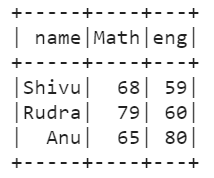
res_df.show()
+-----+----+---+
| Name|Math|Eng|
+-----+----+---+
|Rudra| 79| 60|
|Shivu| 68| 59|
| Anu| 65| 80|
+-----+----+---+