Problem Statement: -
Find out cumulative purchases of each product over time.
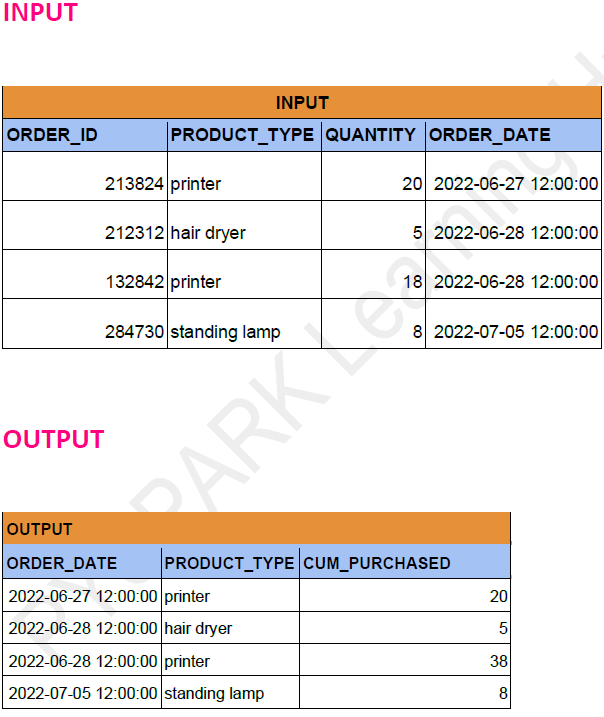
Dataframe API Solution: -
# Define schema for the DataFrame
schema = StructType([ StructField("order_id", IntegerType(), True), StructField("product_type", StringType(), True), StructField("quantity", IntegerType(), True), StructField("order_date", StringType(), True), ])
# Define data # Define data
data = [ (213824, 'printer', 20, "2022-06-27"), (212312, 'hair dryer', 5, "2022-06-28 "), (132842, 'printer', 18, "2022-06-28"), (284730, 'standing lamp', 8, "2022-07-05") ]
df = spark.createDataFrame(data,schema)
df.show()
+--------+-------------+--------+-----------+
|order_id| product_type|quantity| order_date|
+--------+-------------+--------+-----------+
| 213824| printer| 20|2022-06-27 |
| 212312| hair dryer| 5|2022-06-28 |
| 132842| printer| 18|2022-06-28 |
| 284730|standing lamp| 8|2022-07-05 |
+--------+-------------+--------+-----------+
window_spec = Window.partitionBy("Product_type").orderBy("order_date").rowsBetween(Window.unboundedPreceding,Window.currentRow)
result_df = df.withColumn("Cum_Purchased",sum("Quantity").over(window_spec)) \
.select("order_date","Product_type","Cum_Purchased")
result_df.show()
+-----------+-------------+-------------+
| order_date| Product_type|Cum_Purchased|
+-----------+-------------+-------------+
|2022-06-28 | hair dryer| 5|
|2022-06-27 | printer| 20|
|2022-06-28 | printer| 38|
|2022-07-05 |standing lamp| 8|
+-----------+-------------+-------------+
Spark SQL Solution: -
df.createOrReplaceTempView("products")
result = spark.sql("""
SELECT
Order_date,
Product_type,
SUM(Quantity) OVER (PARTITION BY Product_Type ORDER BY Order_date) AS Cum_Purchased
FROM products
""")
result.show()