Problem Statement: -
Dataframe API Solution: -
from pyspark.sql.types import *
from pyspark.sql.functions import *
from pyspark.sql.window import *
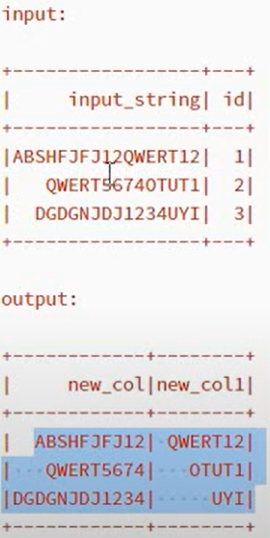
data=[('ABSHFJFJ12QWERT12',1),('QWERT5674OTUT1',2),('DGDGNJDJ1234UYI',3)]
df=spark.createDataFrame(data,schema="input_string string,id int")
df.show()
+-----------------+---+
| input_string| id|
+-----------------+---+
|ABSHFJFJ12QWERT12| 1|
| QWERT5674OTUT1| 2|
| DGDGNJDJ1234UYI| 3|
+-----------------+---+
df1 = df \
.withColumn("new_col", regexp_extract(df.input_string, "(^[a-zA-Z]*[0-9]*)", 1)) \
.withColumn("new_col1", regexp_extract(df.input_string, "(^[a-zA-Z]*[0-9]*)([a-zA-Z]*[0-9]*$)", 2)) \
.drop("input_string", "id")
df1.show()
+------------+--------+
| new_col|new_col1|
+------------+--------+
| ABSHFJFJ12| QWERT12|
| QWERT5674| OTUT1|
|DGDGNJDJ1234| UYI|
+------------+--------+