Problem Statement: -
Given csv file like
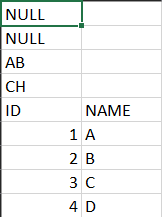
Load it to a dataframe.
RDD Approach: -
rdd = sc.textFile("Files/Book1.csv")
rdd.collect()
['NULL,', 'NULL,', 'AB,', 'CH,', 'ID,NAME', '1,A', '2,B', '3,C', '4,D']
rdd1 = rdd.zipWithIndex()
rdd1.collect()
[('NULL,', 0),
('NULL,', 1),
('AB,', 2),
('CH,', 3),
('ID,NAME', 4),
('1,A', 5),
('2,B', 6),
('3,C', 7),
('4,D', 8)]
rdd2 = rdd1.filter(lambda a:a[1]>3)
rdd2.collect()
[('ID,NAME', 4), ('1,A', 5), ('2,B', 6), ('3,C', 7), ('4,D', 8)]
rdd3 = rdd2.map(lambda a:a[0].split(","))
rdd3.collect()
[['ID', 'NAME'], ['1', 'A'], ['2', 'B'], ['3', 'C'], ['4', 'D']]
header = rdd3.first()
data = rdd3.filter(lambda a:a!=header)
data.collect()
df = data.toDF(header)
df.show()
df.printSchema()
+---+----+
| ID|NAME|
+---+----+
| 1| A|
| 2| B|
| 3| C|
| 4| D|
+---+----+
root
|-- ID: string (nullable = true)
|-- NAME: string (nullable = true)
Read Mode Approach: -
from pyspark.sql.types import *
cols=StructType ([StructField ('id' ,IntegerType ()) , (StructField( 'name', StringType ())) ])
df=spark.read.option('mode','DROPMALFORMED').schema(cols).format('csv').load('Files/Book1.csv')
df.show()