Problem Statement: -
Given text file like: -
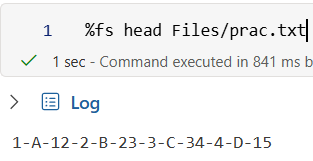
Form a dataframe, like ID, Name, Age.
Dataframe API Solution: -
df = spark.read.csv("Files/prac.txt").withColumnRenamed("_c0","Value")
df.show()
+--------------------+
| Value|
+--------------------+
|1-A-12-2-B-23-3-C...|
+--------------------+
re_expr = "(.*?\\-){3}"
df1 = df.withColumn("New_Val",regexp_replace("_c0",re_expr,"$0,")).drop("_c0")
df1.show()
+--------------------+
| New_Val|
+--------------------+
|1-A-12-,2-B-23-,3...|
+--------------------+
df2 = df1.withColumn("Value_Final",explode(split("New_Val","-,"))).drop("New_Val")
df2.show()
+-----------+
|Value_Final|
+-----------+
| 1-A-12|
| 2-B-23|
| 3-C-34|
| 4-D-15|
+-----------+
df3 = df2.withColumn("ID",split("Value_Final","-")[0]) \
.withColumn("Name",split("Value_Final","-")[1]) \
.withColumn("Age",split("Value_Final","-")[2]).drop("Value_Final")
df3.show()
+---+----+---+
| ID|Name|Age|
+---+----+---+
| 1| A| 12|
| 2| B| 23|
| 3| C| 34|
| 4| D| 15|
+---+----+---+