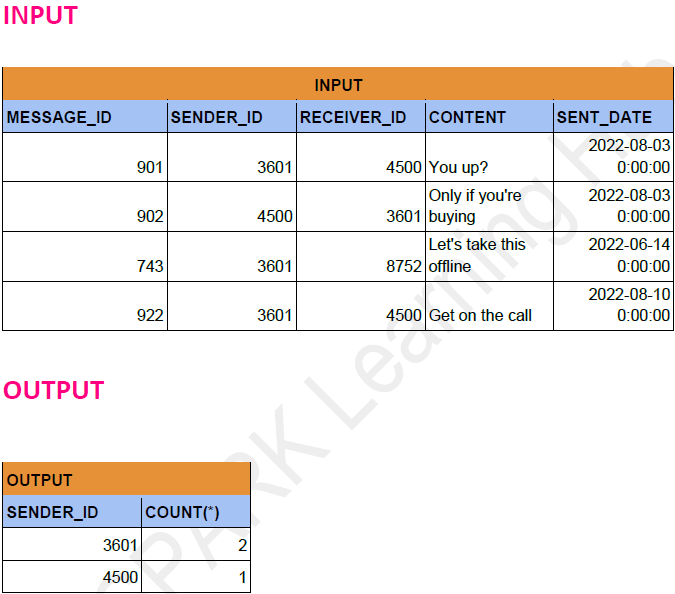
Problem Statement: -
Identify the top 2 Power Users who sent the highest number of messages in Aug 2022.
Display the IDs of these 2 users along with the total number of messages in desc order.
Dataframe API Solution: -
schema = StructType([ StructField("message_id", IntegerType(), True), StructField("sender_id", IntegerType(), True), StructField("receiver_id", IntegerType(), True), StructField("content", StringType(), True), StructField("sent_date", StringType(), True), ])
# Define the data
data = [ (901, 3601, 4500, 'You up?', '2022-08-03 00:00:00'), (902, 4500, 3601, 'Only if you\'re buying', '2022-08-03 00:00:00'), (743, 3601, 8752, 'Let\'s take this offline', '2022-06-14 00:00:00'), (922, 3601, 4500, 'Get on the call', '2022-08-10 00:00:00'), ]
df = spark.createDataFrame(data,schema)
df = df.withColumn("sent_date",to_timestamp("sent_date","yyyy-MM-dd HH:mm:ss"))
df.printSchema()
root
|-- message_id: integer (nullable = true)
|-- sender_id: integer (nullable = true)
|-- receiver_id: integer (nullable = true)
|-- content: string (nullable = true)
|-- sent_date: timestamp (nullable = true)
filtered_df = df.filter(month(col("sent_date")) == 8).groupBy("sender_id").count().orderBy(desc("Count")).limit(2)
filtered_df.show()
+---------+-----+
|sender_id|count|
+---------+-----+
| 3601| 2|
| 4500| 1|
+---------+-----+
Spark SQL Solution: -
df.createOrReplaceTempView("msgs")
result = spark.sql("""
SELECT
sender_id,
COUNT(*) AS CNT
FROM msgs
WHERE MONTH(to_date(sent_date,"yyyy-MM-dd")) = 8
GROUP BY sender_id
ORDER BY CNT DESC
LIMIT 2
""")
result.show()