#stratascratch
https://www.youtube.com/watch?v=pE_a5W70Hu8&list=PLqGLh1jt697zXpQy8WyyDr194qoCLNg_0&index=1
Problem Statement: -
Which user flagged the most distinct videos that ended up approved by YouTube? Output, in one column, their full name or names in case of a tie. In the user's full name, include a space between the first and the last name.
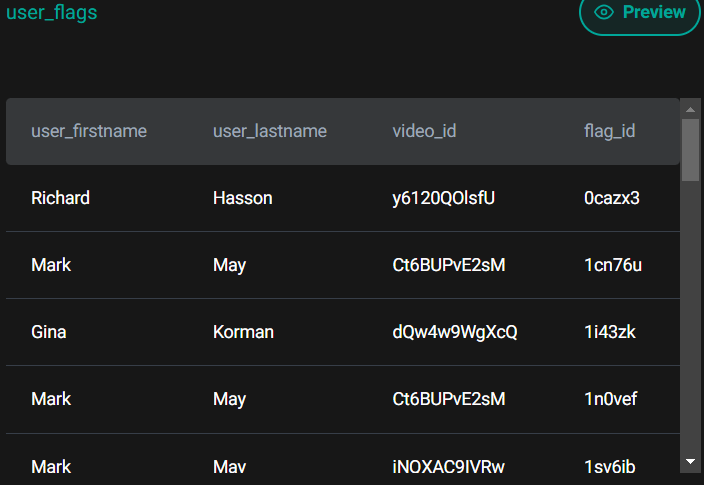
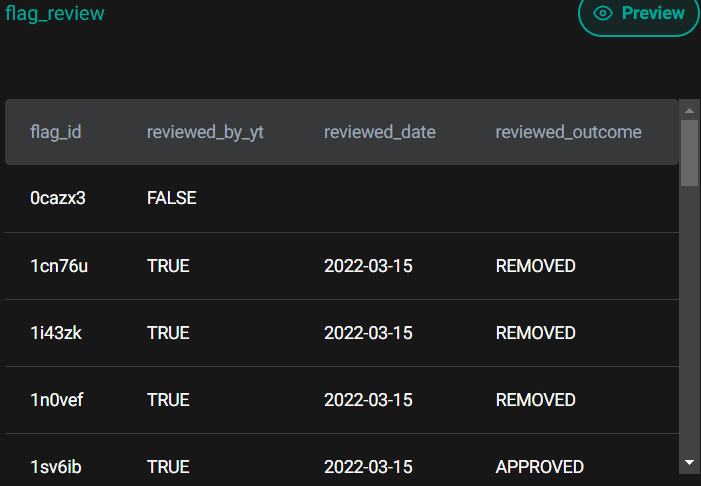
Dataframe API Solution: -
# Import required PySpark libraries
import pyspark
from pyspark.sql.functions import col, trim, concat_ws, countDistinct, rank
from pyspark.sql.window import Window
# Assume user_flags and flag_review DataFrames are defined
user_flags = user_flags
# user_flags.show()
# Filter approved reviews
aprvd_df = flag_review.filter(
(col("reviewed_outcome") == "APPROVED") & (col("reviewed_by_yt") == "true")
)
# aprvd_df.show()
# Join DataFrames and clean up user names
df_joined = user_flags.join(
aprvd_df, user_flags.flag_id == aprvd_df.flag_id, "inner"
).withColumn(
"user_firstname", trim(col("user_firstname"))
).withColumn(
"user_lastname", trim(col("user_lastname"))
)
# df_joined.show()
# Create a full name column and drop unnecessary columns
df_final = df_joined \
.withColumn("Full Name", concat_ws(" ", col("user_firstname"), col("user_lastname"))) \
.drop("user_firstname", "user_lastname", "reviewed_by_yt")
# df_final.show()
# Aggregate data to count distinct video IDs per user
df_cntd = df_final.groupBy("Full Name").agg(
countDistinct("video_id").alias("Cnt")
)
# df_cntd.show()
# Apply window function to rank users by count and filter the top user
window = Window.orderBy(col("Cnt").desc())
df_res = df_cntd.withColumn("rank", rank().over(window)).filter(
col("rank") == 1
).drop("Cnt", "rank")
# Convert result to Pandas DataFrame for final output
df_res.toPandas()